As digitalization progresses, printed and electronic manuals are replaced by modular and intelligent information that is available online. But can information be intelligent? It cannot when existing on its own. It can become intelligent when it is used in smart applications. For that, intelligent information must have certain properties:
- From the reader's point of view, the information is modular and suitable for various application scenarios, target groups, and contexts.
- From the processing point of view, the information can be integrated from various sources, can be retrieved individually, and dynamically compiled into temporary documents. The information enables interaction with the user.
- From a technical point of view, information is format-neutral, structured, and processable; suitable for various devices and enriched with metadata.
Today, we encounter intelligent information in marketing materials, in wikis, on websites, and in technical documentation. Documents are broken down into many individual components that users and applications can retrieve and process separately.
The Purpose of Content Delivery
In recent years, content delivery has made its way into technical communication. The term content delivery describes the technologies that are used to make content digital and as such available to the user. Wolfgang Ziegler defines "content delivery portals" (CDP) as follows [2]: "CDP provide web-based delivery of modular or aggregated information to different target audiences using content-related search mechanisms.” Simply put, content delivery portals are web shops for information. However, the focus is not on sales but on the efficient delivery of the information that the user needs. Until recently, this information has been delivered mostly in the form of pdf files which users can download from a portal. Now the landscape is changing: Information can be categorized and delivered in smaller chunks thanks to component content management systems and topic-oriented writing. The transition from documents to intelligent information has begun. Users can find the information more easily and no longer have to scroll through long documents [3].
Metadata Is Key
Metadata makes content accessible by describing the target audience and contexts of the content. Machine-readable metadata delivered with the content enables smart applications, such as a content delivery portals, to intelligently select, filter and assemble information. This is how metadata makes our content intelligent.
Digital product information particularly needs the following classes of metadata:
- Identification of the product and the component
- Target audience
- Use case, for example a task or a life cycle phase of the product
- Error scenarios
- Required resources such as time, tools, or operating equipment
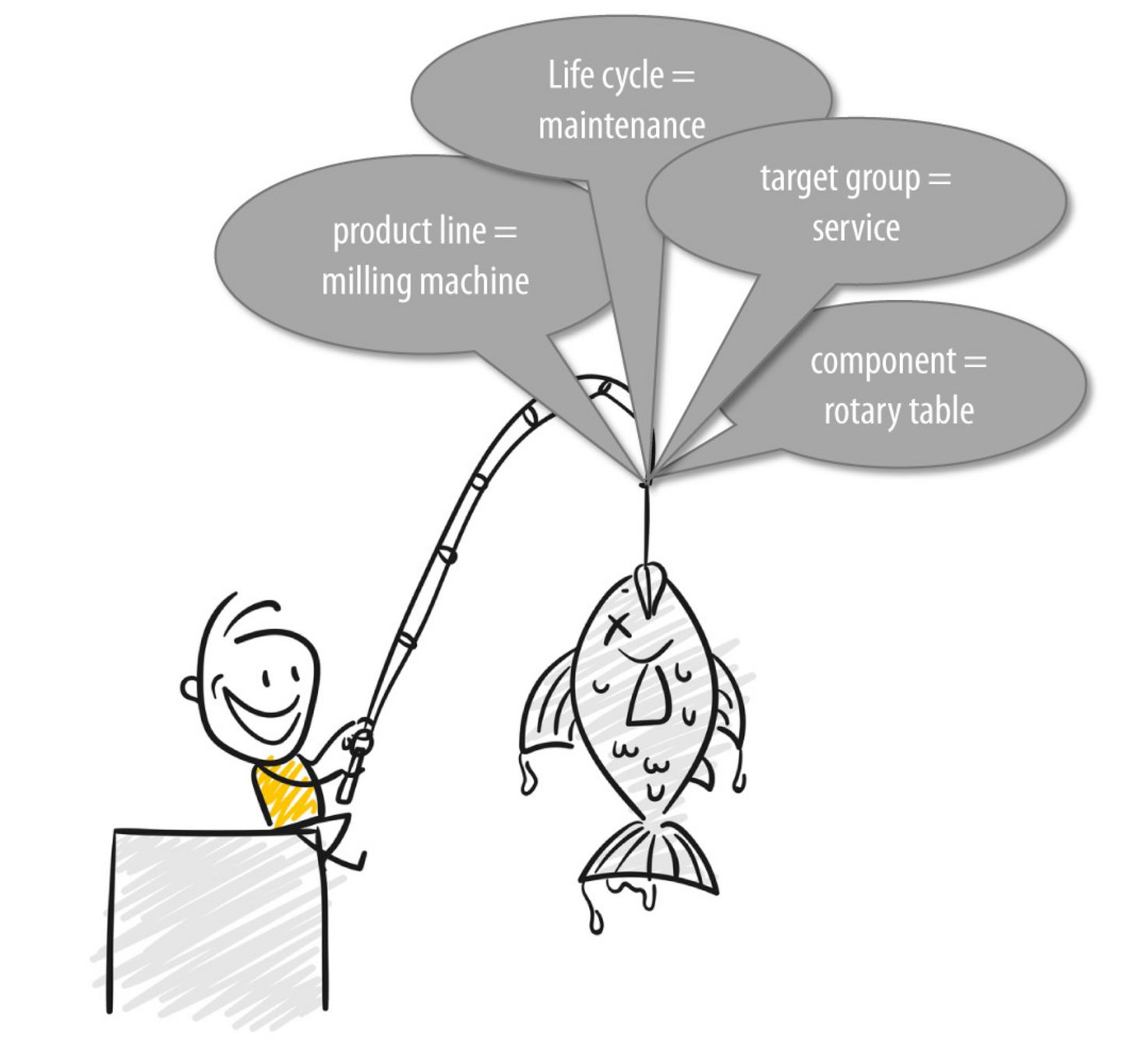
Metadata is like bait on a fishing rod - it helps us to catch the right fish from the big information pond. [Source: strichfiguren.de; Fotolia]
Adding Value to Products
Even though manufacturers provide technical documentation for each technical product, they often do not recognize the commercial value of the information that is hidden in the documentation. Customers are not interested in long manuals or heavy ring binders. Rather than extensive documentation, customers expect a good service that helps them.
If you compare the manufacturer's and the user's point of view, you see that they are two sides of the same coin: If manufacturers offer their users intelligent information, both benefit: The manufacturer increases the value of the product and the user needs less time searching for the right information. And time is money. Manufacturers also gain an advantage in the market: As the products of their competitors become more and more similar to theirs, they can strengthen their position by offering better service – with intelligent information.
Publishing intelligent technical documentation on corporate websites or portals, possibly in combination with marketing content, also increases the visibility and reach of corporate content. Technical documentation usually contains the key terms that customers use in internet queries.
Therefore, intelligent information creates new opportunities for companies to stand out from their competitors, improve customer service, and increase visibility. In this way, companies also make technical documentation a higher priority.
There are some common scenarios for intelligent information in content delivery portals:
- Service portals for service employees
- Self-service portals for customers
- Portals for call-center employees
- Guided troubleshooting and diagnosis
In all these scenarios, users are efficiently guided to the information that they need in a particular context.
iiRDS at a Glance
With iiRDS (intelligent information Request and Delivery Standard), tekom aims at defining a non-proprietary standard for the delivery and exchange of intelligent information. A standard is necessary because metadata can only be used across products and manufacturers if it uses the same vocabulary. Even applications can integrate the documentation of different manufacturers only if they can rely on a common exchange format and a manufacturer-independent vocabulary. iiRDS consists of the following:
- A vocabulary for the metadata that is delivered with the content. The vocabulary is limited to the domain of technical documentation; the technical format used is RDF [4].
- A package format for the exchange of intelligent information between applications, for example, content delivery portals, web portals, and component content management systems. ZIP is used as the technical format.
- The specification that explains the structure of the metadata model and package format.
The iiRDS Consortium is responsible for maintaining the standard. Its members are industrial companies, manufacturers of content management systems, service providers, and associations [5].
Metadata Model Overview
iiRDS metadata can be assigned to text fragments, topics, or documents. The metadata model is based on the PI classification [6] and defines the following types of metadata:
Information type
- Topic type, for example, task, concept, reference
- Document type, for example, service instructions and operating instructions
- Information subject, for example, safety and technical data
Product metadata
- Component
- Product variant
- Product feature
- Product life cycle phase
Functional Metadata
- Events, such as errors
- Planning times, such as maintenance intervals and working time
- Required qualification of the target group
- Tools, spare parts, and consumables
Management metadata
- Identification and status of content, product, and component
- Responsible organization
Navigation metadata for building directory structures
The Package Format
An iiRDS package is technically a ZIP container. It contains the content to be delivered and the associated metadata as RDF. iiRDS defines two variants for the content format:
- Non-restricted packages contain content in any format, such as PDF, HTML, XML, MP4, SVG, or Office files.
- Restricted packages in the so-called iiRDS/A format contain a limited set of file formats and are self-contained. Default formats are PDF/A, a limited media format selection, and XHTML5 with element and attribute restrictions. iiRDS packages are self-contained if the content files only contain references to files within the packages.
The restrictions of the iiRDS/A format ensure that all iiRDS-capable applications can process and display the content in the same or similar ways and with minimum technical effort.
Use of iiRDS in CDP
Content delivery portals can use the iiRDS metadata and the delivered content for various functions, such as search (Fig. 02).
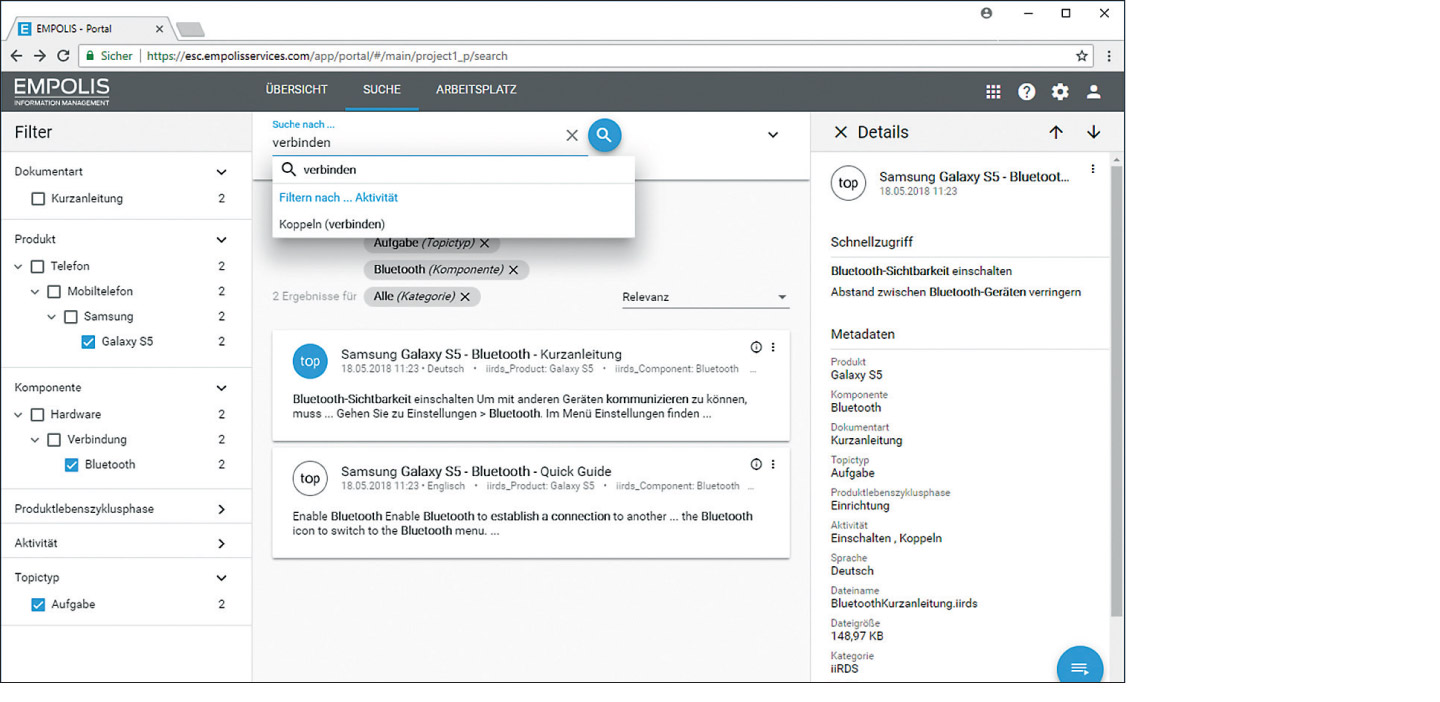
Search in “Empolis Express Service”. [Source: Empolis]
The faceted search (Figure 2, in the screenshot on the left) allows users to quickly narrow down the relevant information (product: "Galaxy S5", component: "Bluetooth").
The semantic search ("Search for") narrows down the information further. The portal suggests suitable concepts for the search (here: "Pair (connect)").
In the example, the entries directly lead to the best hit - the topic "Switch on Bluetooth visibility" in the "Bluetooth Quick Start Guide" (Fig. 03).
Both search mechanisms use the metadata and taxonomies imported via iiRDS.
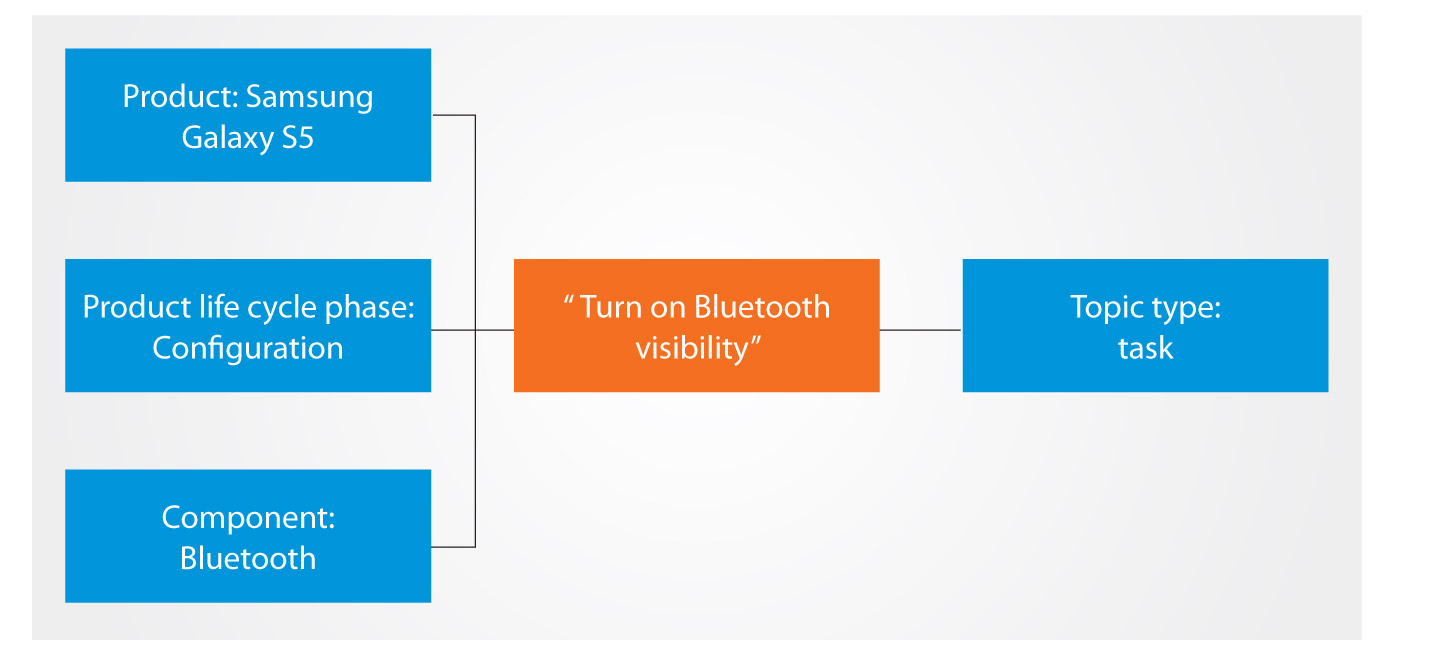
Classification of the topic "Switch on Bluetooth visibility" with iiRDS metadata; the left side shows the product-related metadata, the right side shows the information-related ones. [Source: Empolis].
Content delivery portals also can use knowledge from other sources and link it to the information to create an even better search experience for the user. For example, you can use terminology lists and your own product taxonomies.
iiRDS provides the highway for transporting intelligent information as iiRDS packages. The content delivery portals "stock up" with iiRDS packages to make the information in these packages accessible to their users. Without standardization, CDPs only could read their own packages. Thanks to iiRDS, this works across vendors.
But creating intelligent information involves more than content delivery and iiRDS.
Process for Intelligent Information
iiRDS focuses on the delivery format for intelligent information and the vocabulary used to index and find information. However, a business process that creates intelligent information is complex. You need more than a tool that creates iiRDS: You need an authoring or content management system for the content and metadata, an iiRDS generator for generating the iiRDS packages, and an iiRDS consumer for importing, linking and displaying the intelligent information (Fig. 04).
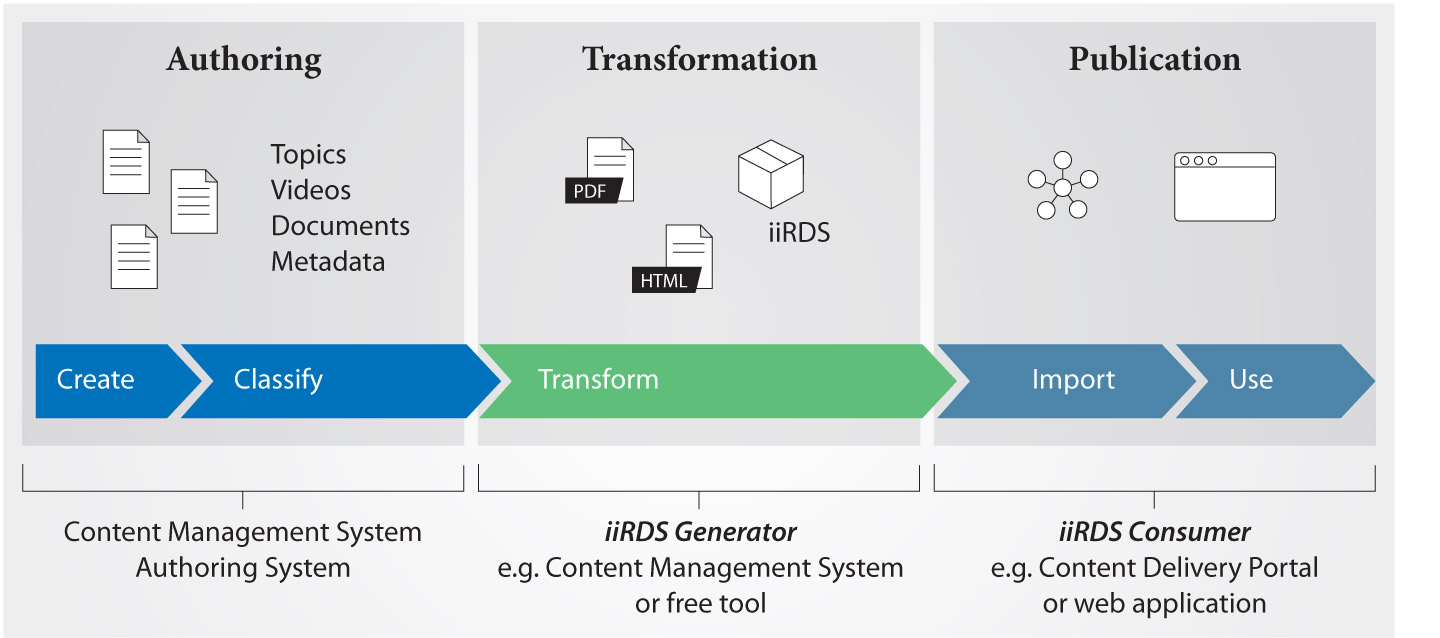
Process for intelligent information. [Source: Martin Kreutzer and Ulrike Parson]
Creation of Intelligent Information
The creation process includes content and the metadata used to categorize it.
How do I write modular content? Authoring intelligent information fundamentally differs from writing classic documents and manuals: The content may come from different sources. Users retrieve it as chunks in different usage scenarios. As an author, you do not know the context in which the content appears, how much the users have read before, and how much they know.
Each piece of content (we call it topic) must therefore be self-contained. Self-contained topics have the following characteristics [7]:
- The topic answers exactly one question, for example "How do I do this?", "What is this?" and "How does it that work?".
- The topic belongs to one information type, for example, instructive, descriptive, or defining.
- The topic is intended for a defined target group and adapted to their reading habits and expectations.
- The level of detail within the topic always remains the same.
In order for our chunks to not stand alone and still provide the big picture, they need context. That means we need to link them, richly. Context is provided by cross-references to related topics, navigation elements for topic hierarchies, or document directories and keywords based on metadata. The context allows the readers to keep their eyes on the big picture and to find their way in the big sea of topics. The document context may also be helpful here, that is, arranging topics of one subject and for one target audience in a document.
Authoring tools – iiRDS is not an authoring standard, but a delivery standard. To ensure the technical properties of intelligent information, a tool must be able to create structured and modular content, manage and assign metadata, and link content. Most component content management systems and XML‑based authoring environments meet these requirements (Fig. 05). Example: Oxygen XML Author together with the DITA format.
In these authoring environments, the metadata is stored with the content according to the XML schema, such as DITA or DocBook. To use iiRDS, you may have to adapt the metadata schema to the requirements of iiRDS.
In addition to authoring functions, component content management systems also provide features for assigning metadata to content. Usually, the metadata can be configured, and taxonomies can be stored. Many CCMS already support the PI class method and are therefore well prepared for iiRDS. Technical authors use the configured metadata schema to categorize information units in the CCMS, such as topics and documents. Metadata is stored separately from content in the database of the CCMS.
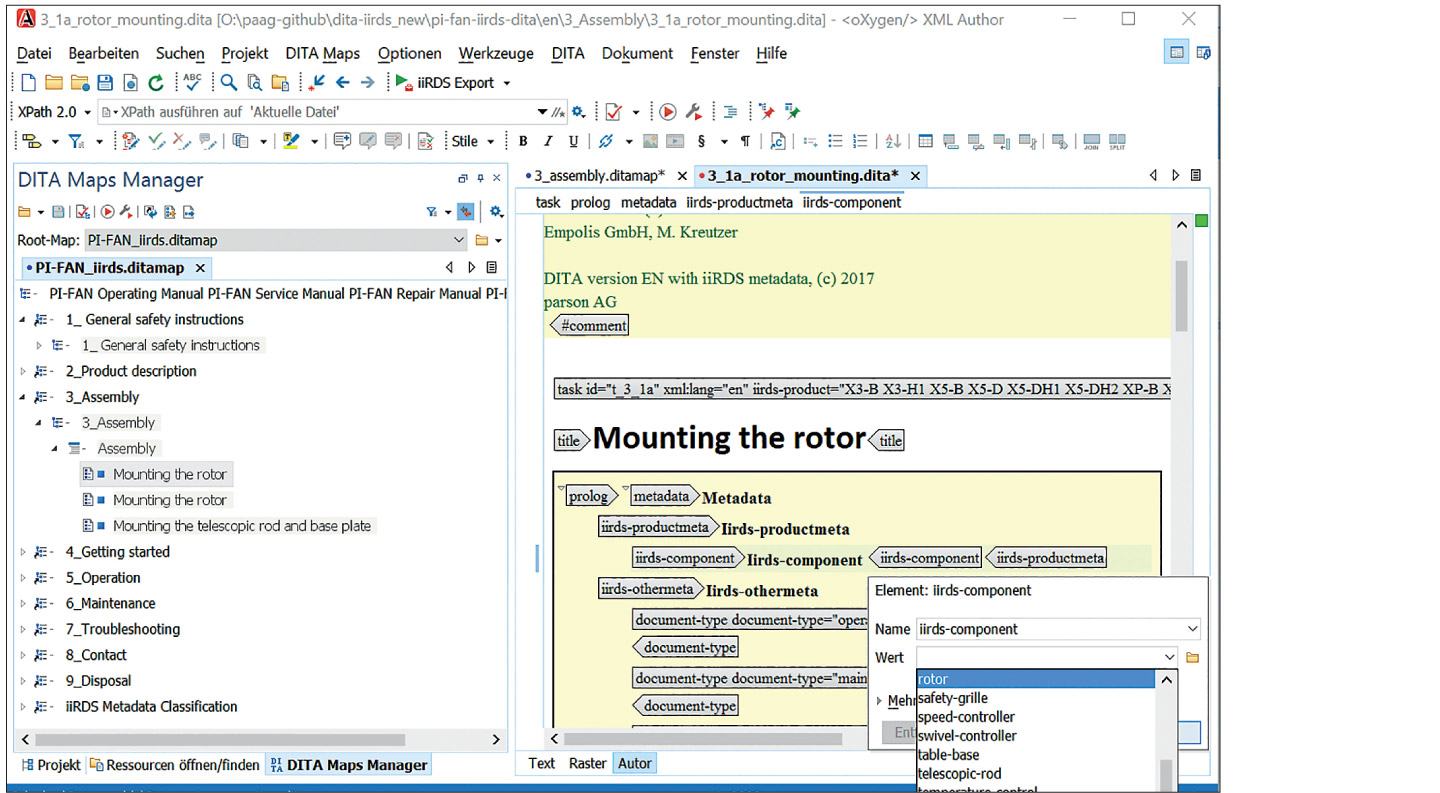
DITA content with iiRDS metadata in Oxygen XML Author, created with the iiRDS plugins by parson and Empolis. The example uses the PI fan [8]. [Source: Martin Kreutzer and Ulrike Parson]
Content Transformation
iiRDS Generators convert modular content and metadata into iiRDS packages. The transformation comprises three important tasks:
- Converting content to the desired target format, for example, HTML or PDF
- Converting metadata to the iiRDS-compliant RDF format
- Assembling metadata, content files, embedded media, stylesheets, and other help files to an iiRDS-compliant package
Transformation tools can be part of a CCMS or authoring system. Several CCMS vendors plan to support iiRDS in their systems.
Apart from content management and authoring systems, there are other tools that help generate iiRDS packages. Standardized formats are a good basis for this transformation, for example:
- DITA Open Toolkit plug-in for publishing a DITA map as an iiRDS package, for example, the parson-Empolis plug-in for DITA [9]
- Publication of a PDF document and separate metadata in Excel format as an iiRDS package
Publication and Use
Systems that process iiRDS packages are called iiRDS Consumers. They read and interpret iiRDS packages and prepare them for use. Content delivery portals with iiRDS import are therefore a type of iiRDS Consumers.
The iiRDS standard does not define the technical implementation of package exchange between a Generator and a Consumer. As of now, there is no standardized protocol or standard interface for this purpose.
When you start to implement iiRDS, your process will look something like this:
- The generated iiRDS package (a ZIP file) must be copied or moved from the file system of the Generator to a directory that the consumer can access.
- A command or a recurring job triggers the import of the iiRDS file by the Consumer.
- When the iiRDS package is imported into a content delivery portal, content and metadata are synchronized with the database, made available in the portal, and indexed for search.
Mastering the Transition
The transition from traditional content creation and publication processes to employing intelligent information represents a major challenge for companies’ documentation departments. But the challenge does not stop there: Intelligent information is generated across different departments because it aggregates information from various sources, for example, training documents, service information, user reports, and operating instructions.
Figure 6 shows a process model for the introduction of intelligent information.
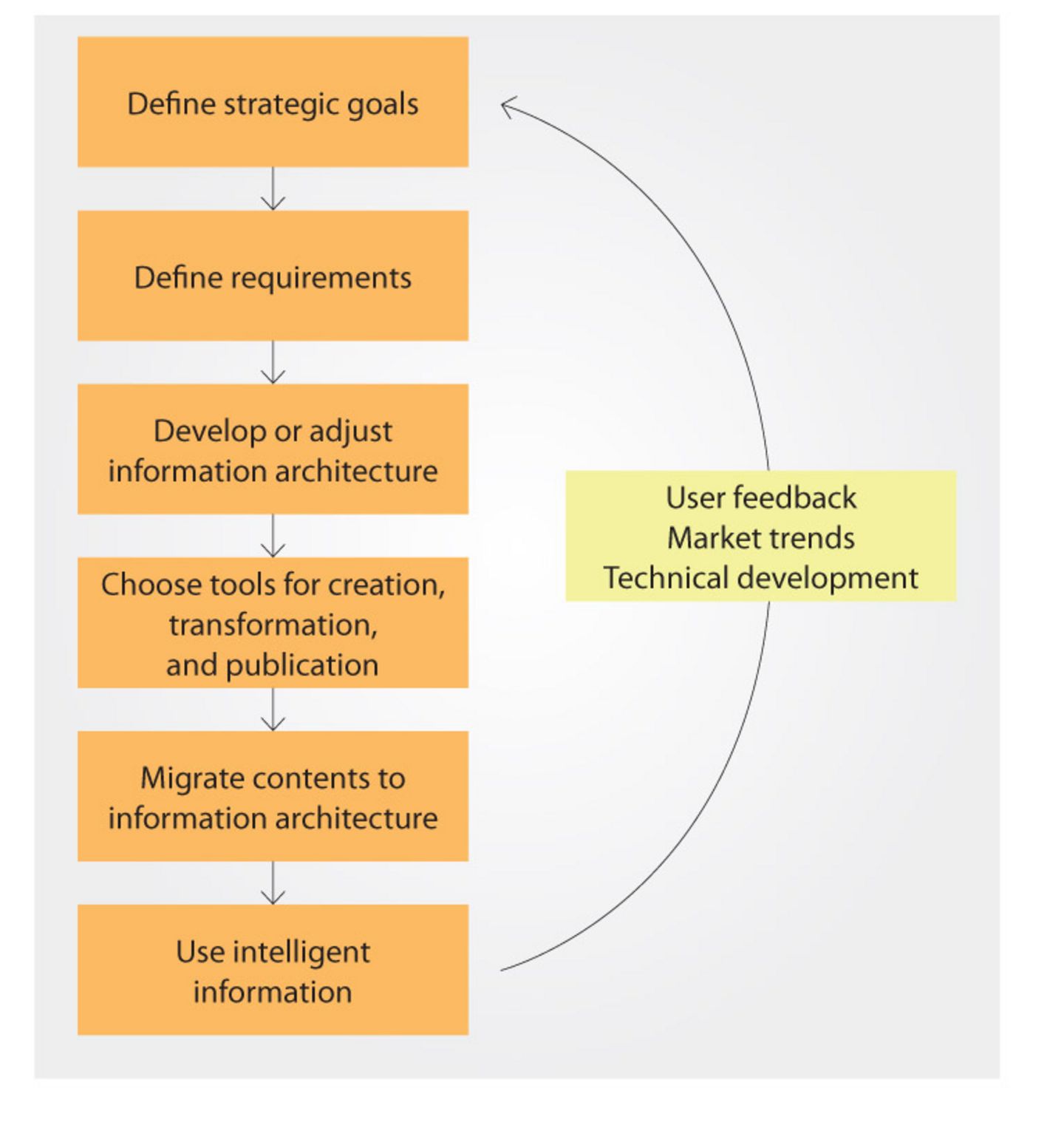
Procedure model for the introduction of intelligent information [Source: Ulrike Parson]
It is important that the transition to intelligent information is part of the corporate digitalization strategy and part of the development of smart, interconnected products and services. Companies that want to employ intelligent information must consider the following:
- Requirements of customers who use digital product information: How and where do they read, what are they looking for, what tools do they use? How do customers benefit from targeted content delivery? What is the customers’ biggest pain regarding the product documentation?
- Sources for intelligent information: In addition to technical documentation, training documents, technical data sheets, service information, or marketing material can be good sources too.
- The system that is used to generate intelligent information. Which is the created format? Which interfaces do these systems provide? How can intelligent information be assembled and merged for joint delivery?
- Where does the information originate and where is it used? What happens if the source changes?
In addition to an XML definition for the structured documentation content, a corporate information architecture also needs to include a structured format for the metadata that enriches the content and is delivered with the content. iiRDS provides a good basis for the development of a sustainable metadata model because the standard already defines the essential metadata classes. The essential metadata classes must be supplemented by company-specific metadata classes, for example, for products, features, and target audiences. An existing PI class model is also a very good basis because the PI metadata can be mapped to the iiRDS metadata in the transformation.
Which tools a company selects for their intelligent content, e.g. authoring environment, iiRDS Generator or content delivery portal, depends on the specific requirements and strategic goals.
The development of intelligent information is an ongoing process that must be continuously aligned with the requirements of users and the market.
Links and Bibliography
[1] tekom (2018): iiRDS – The International Standard for Intelligent Information Request and Delivery. www.iirds.org
[2] Ziegler, Wolfgang (2013): Alles muss raus! Content-Delivery für Informationsportale. Band zur tekom-Jahrestagung.
[3] Kreutzer, Martin; Parson, Ulrike (2018): Machen Sie Ihre technische Dokumentation intelligent – der Weg vom Content Management zu Content Delivery. https://www.empolis.com/blog/digitale-transformation/content-delivery/ oder https://www.parson-europe.com/de/blog/533-machen-sie-ihre-technische-dokumentation-intelligent.html
[4] W3C (editor): Resource Description Framework (RDF). https://www.w3.org/RDF
[5] tekom (2018): iiRDS Consortium Members: www.iirds.org/iirds-consortium/members/
[6] Ziegler, Wolfgang (2016): Ein Fan von Klasse. In: technische Kommunikation. H. 4, S. 38–45.
[7] Baker, Mark (2013): Every Page Is Page One: Topic-Based Writing for Technical Communication and the Web, XML Press.
[8] PI-Fan: http://i4icm.de/forschungstransfer/pi-klassifikation/der-pi-fan/
[9] Knebel, Marion; Kreutzer, Martin (2017): A Marriage for Life? DITA and iiRDS as a Power Couple for Content Delivery. tekom-Jahrestagung. Folien: http://tagungen.tekom.de/fileadmin/tx_doccon/slides/1793_A_Marriage_for_Life_DITA_and_iiRDS_as_a_Power_Couple_for_Content_Delivery.pdf
